Udemy Machine Learing 강의
시작하기 전
- AI 모델링과 FastAPI로 API호출하고 React JS로 연동 및 AWS에 배포작업
- 광주인공지능사관학교에 프로젝트에 필요한 능력
- CI/CD하는 법 배우기(Docker)
- AWS 서버 배포
- 영어자막으로 이해하면서 가기…(ㅜ)

- Python에서 모델을 배포하는 방법
- 모델에 적응할 준비가 된 코드

- 모델을 배포하고 모범사례를 배우려는 데이터 과학자
- 기계학습을 시작하려는 소프트웨어 개발자
- Python 프로그래밍 및 기계학습에 대한 지식
소개

과정 자료
- 코드
- 프레젠테이션
- 데이터 셋
- 기계학습에 대해 자세히 알아볼 수 있는 추가 리소스

- 모델 배포 및 중요한 이유
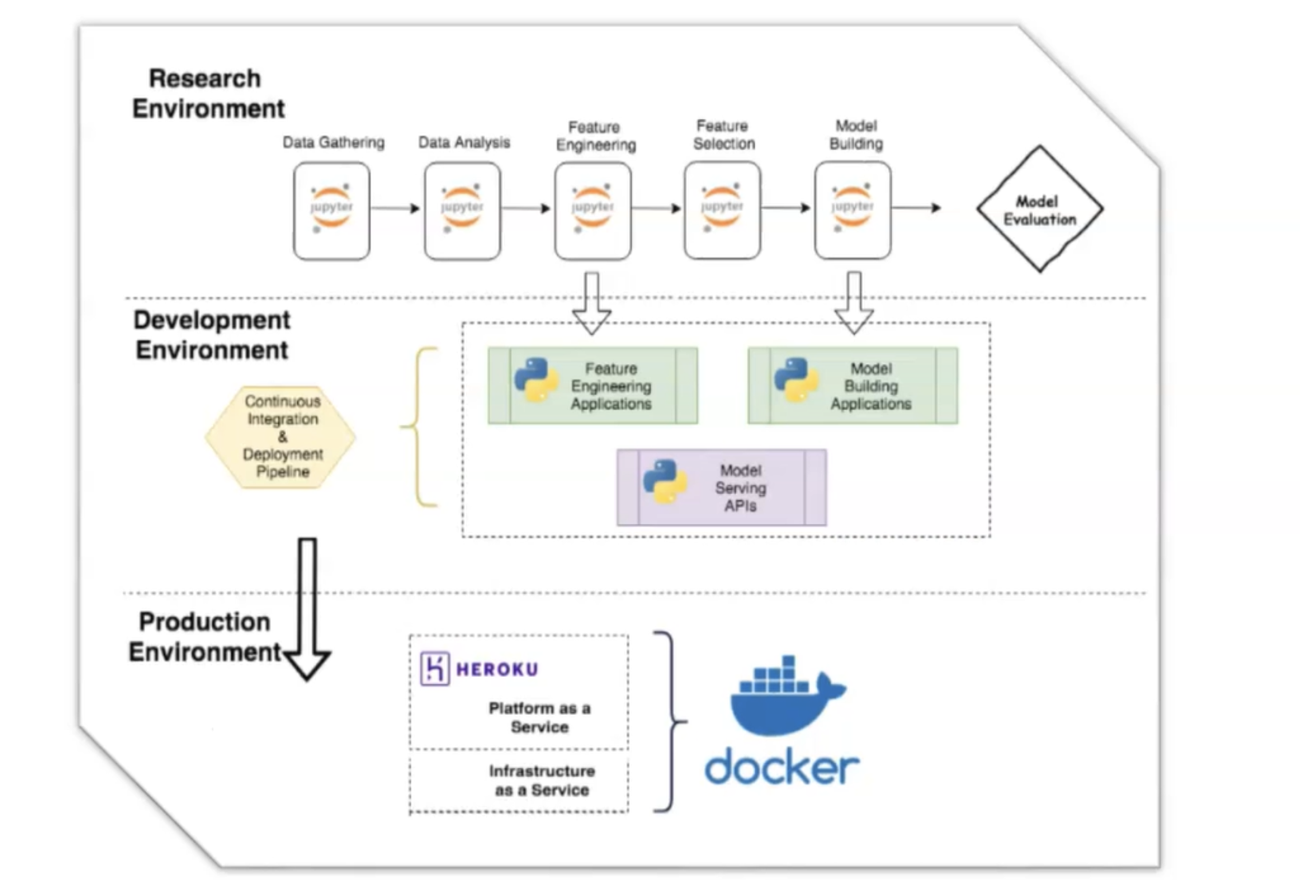
- 연구 및 가상환경
- 기계학습시스템 아키텍처
- 아키텍처 구성요소
- 적합한 시스템 아키텍처를 생성하기 위한 과제 및 원칙
- 다양한 아키택처 접근 방식
- 재현 가능한 파이프라인 구축
- 과제 및 이를 완화하는 방법
Course Requirements(과정 요구사항)




Course Materials(과정 자료)

- 머신러닝 자료[https://github.com/trainindata/deploying-machine-learning-models]
- 프레젠테이션 자료[https://www.dropbox.com/sh/effzx0nmstqcr2e/AAB4sB33hv5jULKj-6cj3XqQa?dl=0]
- DataSet(주택 가격 - 고급 회귀 기법)[https://www.kaggle.com/c/house-prices-advanced-regression-techniques/data]
- 추가 관련 리소스
- 필요한 기술에 대한 추가 리소스 1) 관련 기계 학습 및 데이터 과학 기술에 대해 어떻게 더 배울 수 있습니까?
- Python 프로그래밍에 대해 자세히 알아볼 수 있는 리소스
- R 프로그래밍에 대해 자세히 알아볼 수 있는 리소스
- 기계 학습에 대해 자세히 알아볼 수 있는 리소스
- 데이터 과학에 대해 자세히 알아볼 수 있는 리소스
기계 학습은 매우 광범위한 분야이므로 다양한 알고리즘을 폭넓게 이해하려면 여러 과정과 리소스를 방문해야 할 가능성이 높습니다.
2) 기계 학습을 위한 변수 전처리 및 데이터 정리에 대해 자세히 알고 싶습니다. 이 과정의 마지막 섹션에서 기능 엔지니어링에 대한 종합 과정에 대한 링크를 찾을 수 있습니다. 한편 다음 기사를 살펴보십시오.
- 기계 학습을 위한 기능 엔지니어링: 포괄적인 개요
- 기계 학습을 위한 기능 엔지니어링에 대해 배울 수 있는 최고의 리소스
- Python을 사용한 기능 엔지니어링 기법의 실용적인 코드 구현
3) git에 대해 더 알고 싶은데 어떻게 해야 합니까?
-
여기 Udemy에는 시도할 수 있는 높은 등급의 여러 과정이 있습니다.
-
How to approach rhe course(과정에 접근하는 방법)


기계학습 모델의 배포




기계학습 파이프라인의 배포
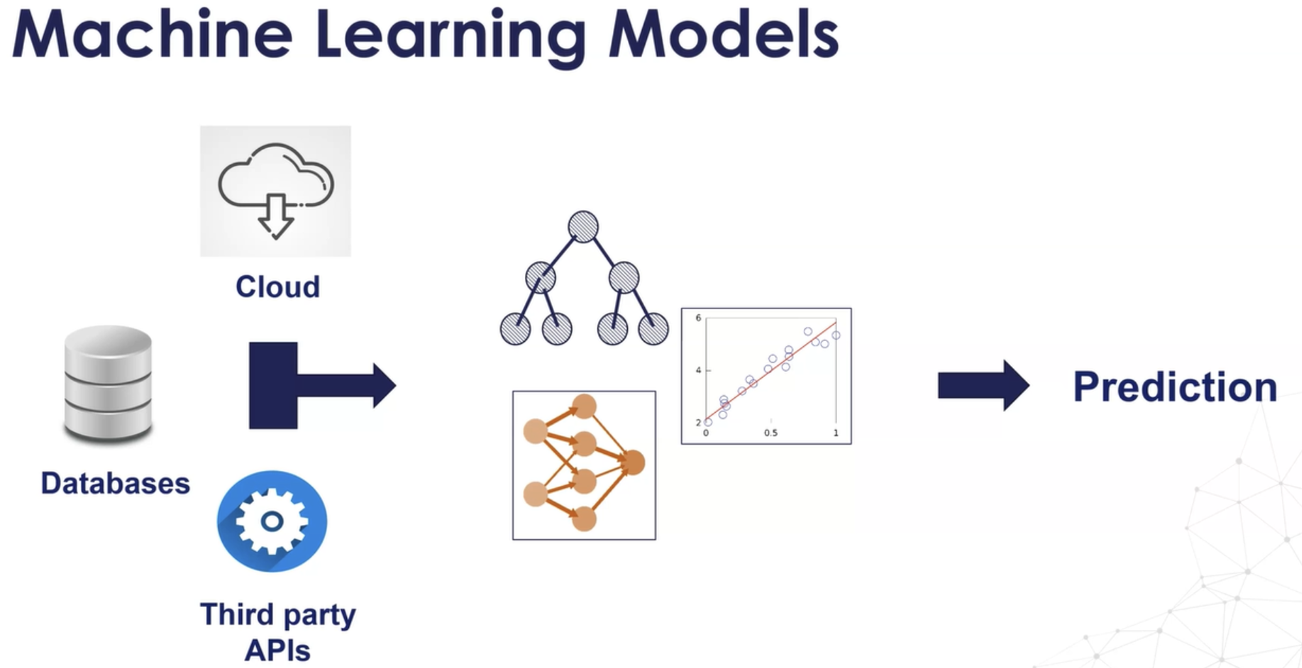
- 기계 학습 모델을 이미징하는 간단한 방법으로 조직은 클라우드의 데이터베이스에 저장하거나 타사의 API에서 검색할 수 있는 일부 데이터를 보유합니다.
- 그런 다음 이러한 데이터를 공급하여 비즈니스에 유용한 몇 가지 예측을 제공할 수 있는 모델을 구축합니다.
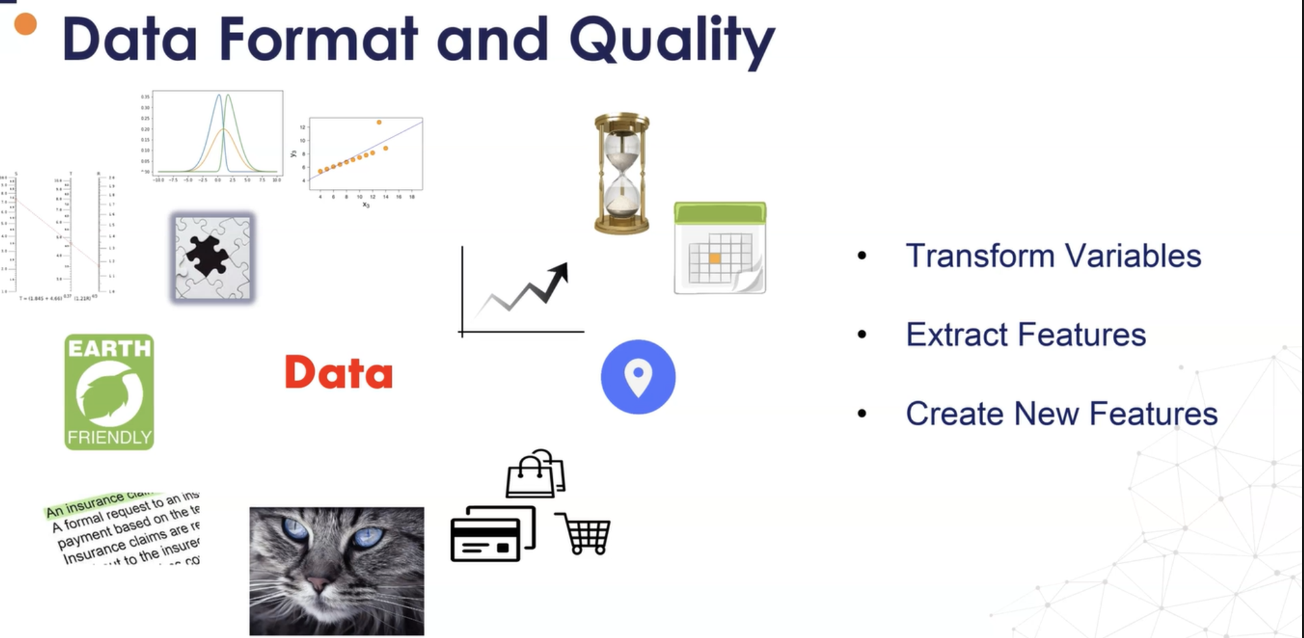
- 그러나 데이터는 기계 학습 모델을 교육하는 데 사용할 준비가 거의 되어 있지 않습니다.
- 실제로 데이터는 형식과 품질 측면에서 다양한 특성을 나타내므로 적합하지 않습니다.
- 예를 들어 데이터 1% 누락된 값과 라이브러리의 일부 튜터링 기계 학습 모델은 데이터 세트의 값 부족을 처리할 수 없습니다.
- 데이터는 또한 숫자 대신 문자열을 포함할 수 있으며 컴퓨터는 다음을 사용하여 계산을 수행할 수 없습니다.
- 그래서 우리는 그것들을 데이터의 변수에 대한 숫자로 변환해야 합니다. 일부 분포와 변수의 분포는 모델의 성능에 영향을 미칠 수 있습니다.
- 데이터는 또한 이상값을 나타낼 수 있고 일부 모델은 이상값의 존재에 민감하므로 이러한 값을 검열하거나 제거하도록 선택과 크기를 조정해야 합니다.
- 때로는 데이터가 텍스트 형식이므로 이 텍스트에서 정보를 추출할 수 있어야 합니다.
- 때로는 계산할 수 있는 일종의 입력으로 데이터를 이미지로 가져오고 다시 이 이미지에서 데이터 또는 프레임을 추출할 수 있어야 합니다.
- 일부 데이터는 트랜잭션일 수 있으며 이 데이터를 집계하여 고객에 대한 보다 간소화된 보기를 가질 수 있습니다.
- 때로는 데이터가 지리적 위치이고 우리는 이 데이터에서 기능을 추출하기를 원합니다.
- 때로는 특정 방식으로 처리하거나 집계해야 하는 시계열이 있고 모델에서 바로 사용할 수 없는 날짜 및 시간 변수가 있을 수 있지만 대신 이러한 데이터를 사용하여 교육하기 전에 많은 변수 변환을 수행해야 합니다
- 하지만 데이터에서 기능을 추출하거나 기존 기능을 결합하여 새로운 기능을 생성해야 합니다.
- 따라서 우리는 모델을 교육하는 것에 대해 이야기하는 것이 아니라 모델을 교육하기에 적합하도록 데이터를 전처리하는 것에 대해서도 이야기하고 있습니다.
- 그리고 때때로 우리는 우리가 사용할 수 있는 모든 기능을 사용하고 싶지 않을 수도 있습니다.
- 우리는 기능 선택 유형을 포함합니다.
- 기계 학습 파이프라인에는 원시 데이터에서 예측을 얻을 수 있도록 기계 학습 모델을 교육하는 데 적합한 데이터 형식으로 이동할 수 있는 다양한 단계가 포함되어 있습니다.
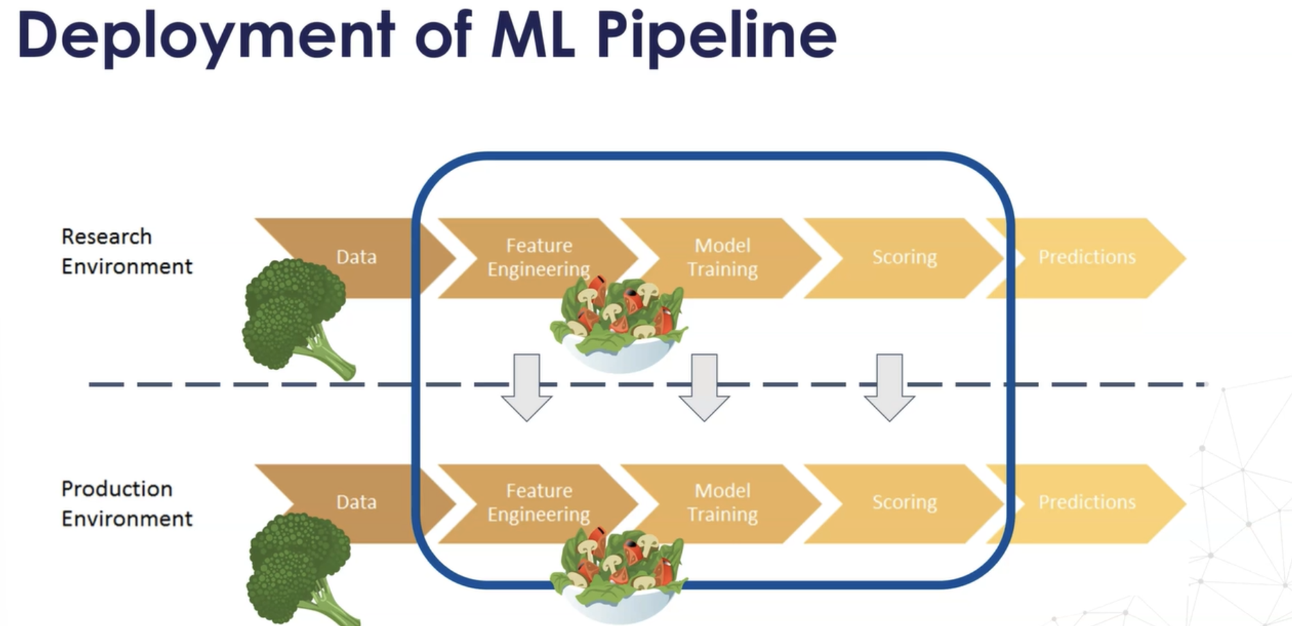
- 기계 학습 모델을 배포할 때 모델 자체를 배포할 뿐만 아니라 전체 파이프라인을 배포해야 합니다.
- 연구와 생산 환경 모두에서 원시 데이터를 받을 가능성이 높기 때문입니다. 따라서 우리는 모델을 훈련하거나 모델이 훈련되면 접두어를 얻을 수 있는 성숙한 데이터를 생성할 수 있는 파이프라인의 단계가 필요합니다.
- 머신 러닝 파이프라인의 여러 단계에 대한 자세한 내용은 섹션 4에서 나중에 설명하겠습니다.
- 나머지 부분에서는 재현 가능한 기계 학습 파이프라인을 구축하는 개념에 중점을 둘 것입니다.
연구 및 생산 환경


재현 가능한 기계학습 파이프라인 구축
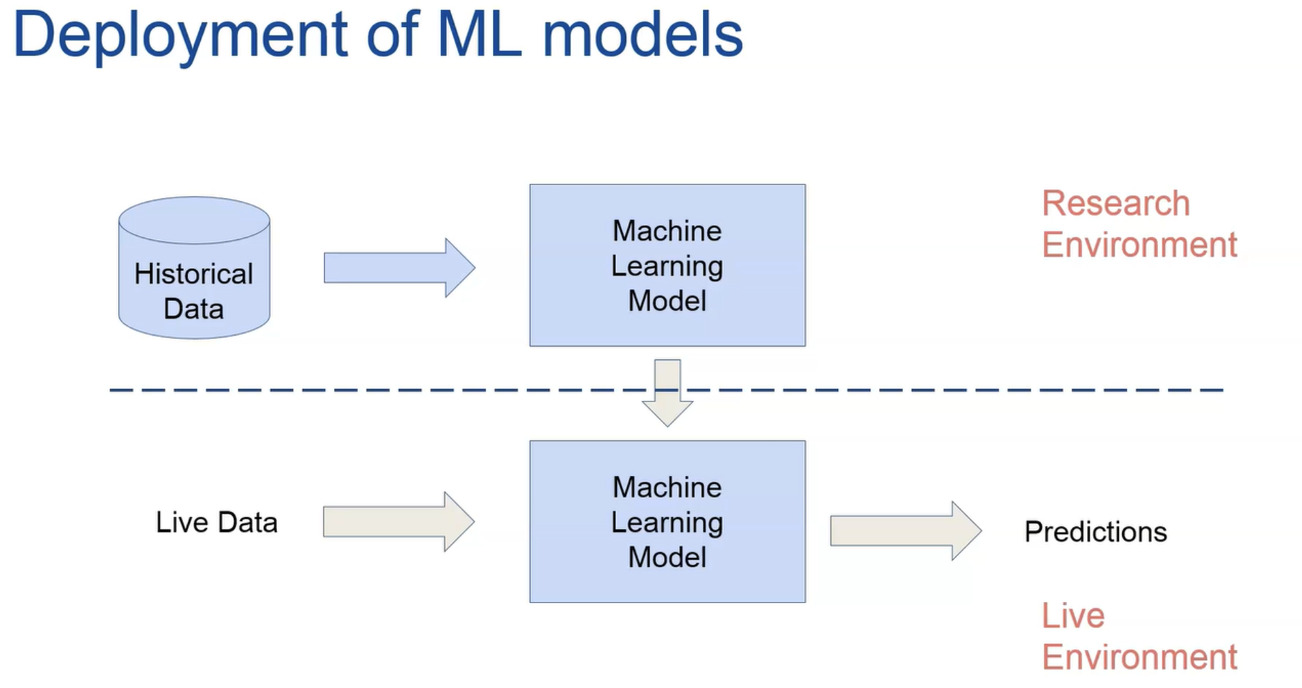
- 기계 학습 모델의 배포는 우리 모델을 프로덕션에서 사용할 수 있도록 만드는 프로세스입니다.
- 다른 소프트웨어 시스템에 예측을 제공할 수 있는 환경을 개발할 것은 소위 연구 환경에서 수행하는 기계 학습 모델입니다.
- 이것은 데이터 사이언티스트가 자유를 가질 때 빅 데이터와 접촉하지 않는 고립된 환경입니다.
- 다양한 모델을 시도하고 연구하고 특정 제품 요구에 대한 솔루션을 찾으려면 일반적인 설정에서 과거 데이터가 있고 이 데이터를 사용하여 기계 학습 모델을 교육합니다.
- 연구 환경에서 모델의 성능에 만족하면 생산 환경으로 모델을 마이그레이션할 준비가 된 것입니다. 여기서 실 데이터에서 입력을 받고 결정을 내리는 데 사용할 수 있는 예측 결과를 출력할 수 있습니다.
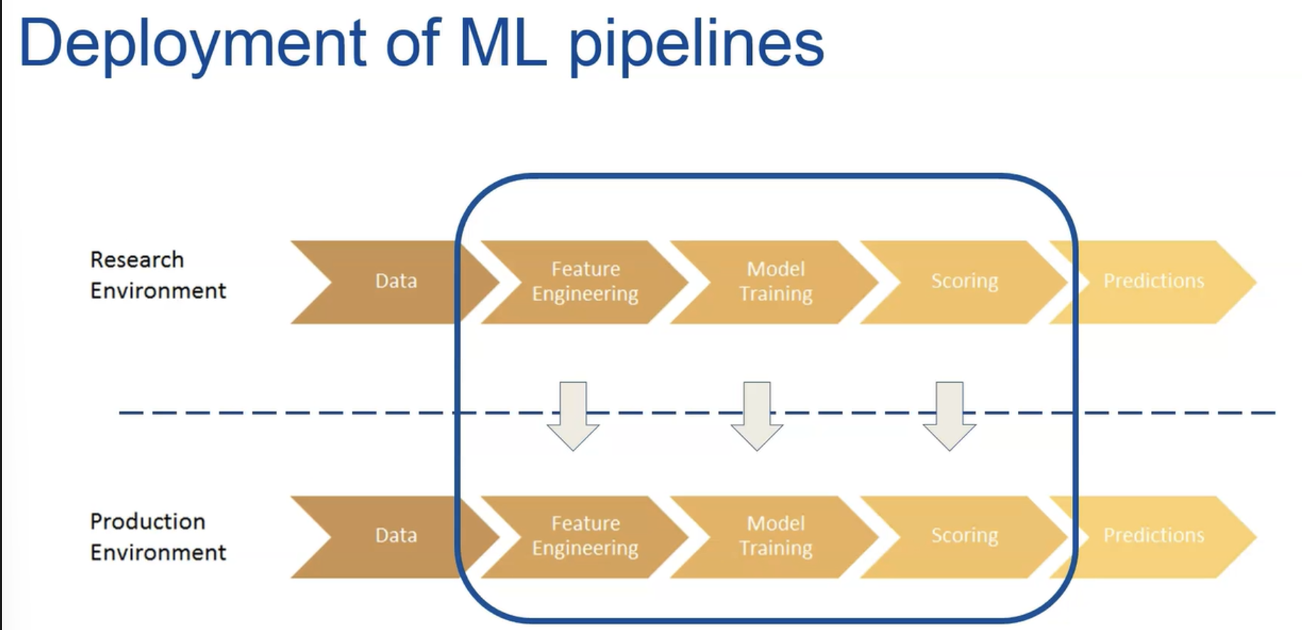
- 실제로 기계 학습 파이프라인의 배포를 의미할 때 기계 학습 모델의 분산에 대해 자주 이야기합니다.
- 데이터를 받은 순간부터 예측을 하는 순간까지 일어나야 하는 일련의 단계입니다.
- 일반적인 기계 학습 파이프라인에는 많은 부분의 기능 변환 단계가 포함됩니다. 아마도 이것은 파이프라인의 가장 큰 부분일 것입니다.
- 그런 다음 기계 학습를 훈련시키는 단계와 연구 환경에서 전체 파이프라인을 생성하는 예측을 출력하는 단계를 포함하여 전체 파이프라인을 생산 환경에 배포해야 합니다.
- 우리는 또한 원시 데이터를 입력으로 받을 것이며 이를 해석하고 예측을 반환할 수 있도록 필요한 기능을 만들기 위해 변환해야 합니다.
- 프로덕션에 파이프라인을 배포할 때 파이프라인을 재현할 수 있는 방식으로 수행해야 합니다.
- 연구 환경의 파이프라인과 프로덕션 환경의 파이프라인이 모두 동일한 원시 데이터 입력을 수신합니다. 두 파이프라인이 동일한 보호를 반환해야 합니다. 동일한 데이터 Khamsin 동일한 출력이 두 파이프라인에서 나와야 합니다.
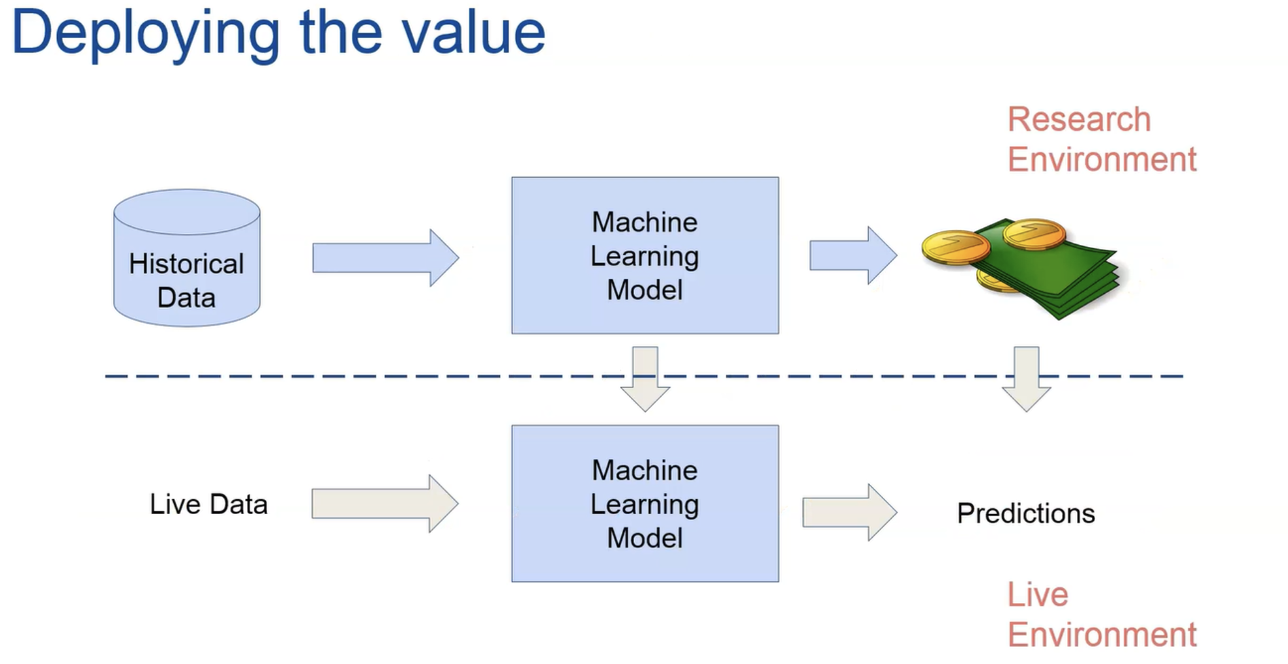
- 우리가 구축하고 성능을 최적화한 프로젝트의 연구 단계가 비즈니스 가치를 극대화한다고 생각하는 이유는 무엇입니까?
- 머신 러닝 파이프라인을 위한 머신 러닝 모델을 개발할 때 정확성, 정밀도와 같은 고전적인 메트릭을 활용하여 통계적 관점에서 모델 성능을 테스트한다고 말해야 합니다.
- 중간 제곱 오차 및 친숙한 기타 메트릭을 기억하십시오. 또한 이러한 매개변수를 비즈니스 가치로 변환하는 메트릭도 평가합니다.
- 예를 들어, 우리는 우리 모델이 창출할 증가된 수익, 증가된 고객 만족도 또는 우리가 관심 있고 조직에 따라 달라지는 다른 측정을 측정할 수 있습니다.
- 제가 연구 환경에서 실생활, 즉 환경에 이르기까지 이 관점에서 보여주는 것처럼 이 수익 증가를 이 값으로 변환하는지 확인해야 합니다.